数据可视化是数据科学中连接数据与决策的关键桥梁。它不仅仅是制作图表,更是一门将原始、复杂的数据集转化为富有洞察力的视觉故事的艺术和科学。通过图形化的方式,我们能够更直观地识别数据中的模式、发现隐藏的趋势、理解变量间的关系并快速定位异常值。在众多数据科学工具中,Python 凭借其简洁的语法和强大的库生态系统,已成为执行数据可视化任务的首选语言。本指南将系统地引导你,从掌握最基础的静态绘图开始,一步步进阶到能够构建复杂、动态的交互式可视化应用。
🎨 为什么选择 Python 进行数据可视化?
Python 在数据科学领域的统治地位并非偶然,其在可视化方面的优势尤为突出:
易于学习与使用 :相较于 R 或 Java 等其他语言,Python 的语法更接近自然语言,使得初学者可以快速上手,将主要精力集中在数据分析本身,而非复杂的编程语法上。强大的库生态系统 :Python 拥有一个无与伦比的开源库集合。
Matplotlib 是这个生态的基石,提供底层的、全面的绘图控制。Seaborn 在 Matplotlib 之上提供了更高级的统计绘图接口,让美观的图表唾手可得。Plotly 和 Bokeh 则将可视化带入了现代 Web 时代,专注于交互性和动态展示。 无缝的社区支持 :得益于其庞大的用户和开发者社区,几乎任何你能想到的可视化问题,都已经有了现成的教程、代码示例或解决方案。Stack Overflow、GitHub 和各类博客是学习路上的宝贵资源。卓越的集成性 :可视化通常是数据处理流程的最后一步。Python 的可视化库能与数据处理的“三驾马车”——Pandas (数据处理) 、NumPy (数值计算) 和 Scikit-learn (机器学习) ——无缝集成,形成一个从数据清洗、分析到可视化的流畅工作流。
Matplotlib:可视化的基石
Matplotlib 是 Python 可视化世界的奠基者和核心。它诞生于 2003 年,其设计初衷是模仿 MATLAB 的绘图功能,因此它拥有一个非常成熟和稳定的 API。几乎所有 Python 中的静态图表,无论多么复杂,都可以用 Matplotlib 实现。学习 Matplotlib 不仅是学习一个库,更是理解图形如何被一层层构建起来的过程——从画布 (Figure) 到坐标系 (Axes),再到线条、点、标签等每一个独立的元素。这种精细的控制力是它最大的优势,也是其略显复杂的根源。
安装 Matplotlib
通过 pip 包管理器可以轻松安装:
基础绘图:解构一张图表
在 Matplotlib 中,推荐使用其面向对象的接口进行绘图,这能让你对图表的各个部分有更清晰的控制。一个基本的绘图流程如下:
创建画布 (Figure) 和坐标系 (Axes) :plt.subplots() 是最常用的方法,它像是在画纸上为你准备好了一块准备作画的区域。在坐标系上绘图 :调用 ax 对象的方法(如 ax.plot(), ax.scatter())来添加数据。定制图表元素 :通过 ax 的 set_ 系列方法(如 set_title(), set_xlabel())来添加标题、坐标轴标签等。显示图形 :最后调用 plt.show() 将最终结果渲染出来。
1. 折线图 (Line Plot)
折线图是展示连续数据趋势最基础也最有效的工具,尤其适合于时间序列数据。
import matplotlib.pyplot as pltimport numpy as np# 准备一组平滑的、有代表性的数据 # np.linspace 在 0 到 10 之间生成 100 个等间距的点 = np.linspace(0 , 10 , 100 )# 计算每个 x 点对应的正弦值 = np.sin(x)# 1. 创建画布(fig)和坐标系(ax) = plt.subplots(figsize= (8 , 5 )) # figsize可以控制图形的尺寸 # 2. 在坐标系(ax)上绘制折线图 # 'label' 参数用于后续图例的生成 = 'sin(x)' , color= 'blue' , linewidth= 2 )# 3. 定制图表的标题和坐标轴标签,增加可读性 'Simple Sine Wave' )'X-axis' )'Y-axis' )# ax.grid(True, linestyle='--', alpha=0.6) # 添加网格线,使数值读取更容易 # 显示图例 # 4. 显示最终的图形
2. 散点图 (Scatter Plot)
散点图是探索两个数值变量之间是否存在关联的利器。每个点代表一个数据样本,其在 x-y 平面上的位置由两个变量的值决定。
import matplotlib.pyplot as pltimport numpy as np# 使用 NumPy 生成两组随机数据来模拟两个变量 42 ) # 设置随机种子以保证结果可复现 = np.random.rand(50 ) * 10 = np.random.rand(50 ) * 10 # 直接使用 plt 接口进行快速绘图,这对于简单图表更便捷 = (8 , 5 )) # 创建一个新画布 = 'red' , alpha= 0.6 , edgecolors= 'black' ) # c是颜色, alpha是透明度, edgecolors是点的边缘颜色 # 添加标题和标签 'Basic Scatter Plot' )'X Value' )'Y Value' )# 显示图形
3. 条形图 (Bar Chart)
当需要比较不同类别之间的数值大小时,条形图是最佳选择。它的高度或长度直观地表示了数值的大小。
import matplotlib.pyplot as plt# 准备离散的类别和它们对应的数值 = ['Group A' , 'Group B' , 'Group C' , 'Group D' ]= [23 , 45 , 58 , 32 ]= (8 , 5 ))# plt.bar() 用于创建垂直条形图,plt.barh() 用于创建水平条形图 = ['#1f77b4' , '#ff7f0e' , '#2ca02c' , '#d62728' ]) # 为每个条形指定不同颜色 # 添加标题和标签 'Categorical Bar Chart' )'Category' )'Value' )# 在每个条形图上方显示具体数值 for i, value in enumerate (values):+ 1 , str (value), ha= 'center' )# 显示图形
4. 直方图 (Histogram)
直方图是理解单个数值变量分布情况的核心工具。它将数值范围分割成若干个“箱子”(bins),然后统计落入每个箱子的数据点数量。
import matplotlib.pyplot as pltimport numpy as np# 生成 1000 个服从标准正态分布的随机数 = np.random.randn(1000 )= (8 , 5 ))# bins 参数非常关键,它决定了分布的精细程度 # edgecolor='black' 让每个条柱的边界更清晰 = 30 , color= 'skyblue' , edgecolor= 'black' )# 添加标题和标签 'Data Distribution Histogram' )'Value' )'Frequency' )# 显示图形
📊 Seaborn:更美观的统计图表
Seaborn 是在 Matplotlib 基础上进行的一次华丽封装。它的出现解决了 Matplotlib 的两大痛点:复杂的参数设置和不够现代的默认样式。Seaborn 的核心理念是让统计绘图变得简单,它提供了大量专门为展示统计信息而设计的图表类型,并且能够直接识别和使用 Pandas DataFrame 的列名,极大地简化了数据准备的过程。你只需要一行代码,就能创建出在 Matplotlib 中可能需要十几行代码才能实现的复杂图表。
安装 Seaborn
pip install seaborn pandas
常用统计图
我们将使用 Seaborn 内置的 tips (餐厅小费) 数据集来展示其强大功能。这个数据集记录了顾客的账单总额、支付的小费、性别、是否吸烟等信息。
import seaborn as snsimport matplotlib.pyplot as plt# Seaborn 加载数据集非常方便 = sns.load_dataset("tips" )# 设置 Seaborn 的美学风格 = "whitegrid" , palette= "muted" )
1. 关系图 (Relational Plot)
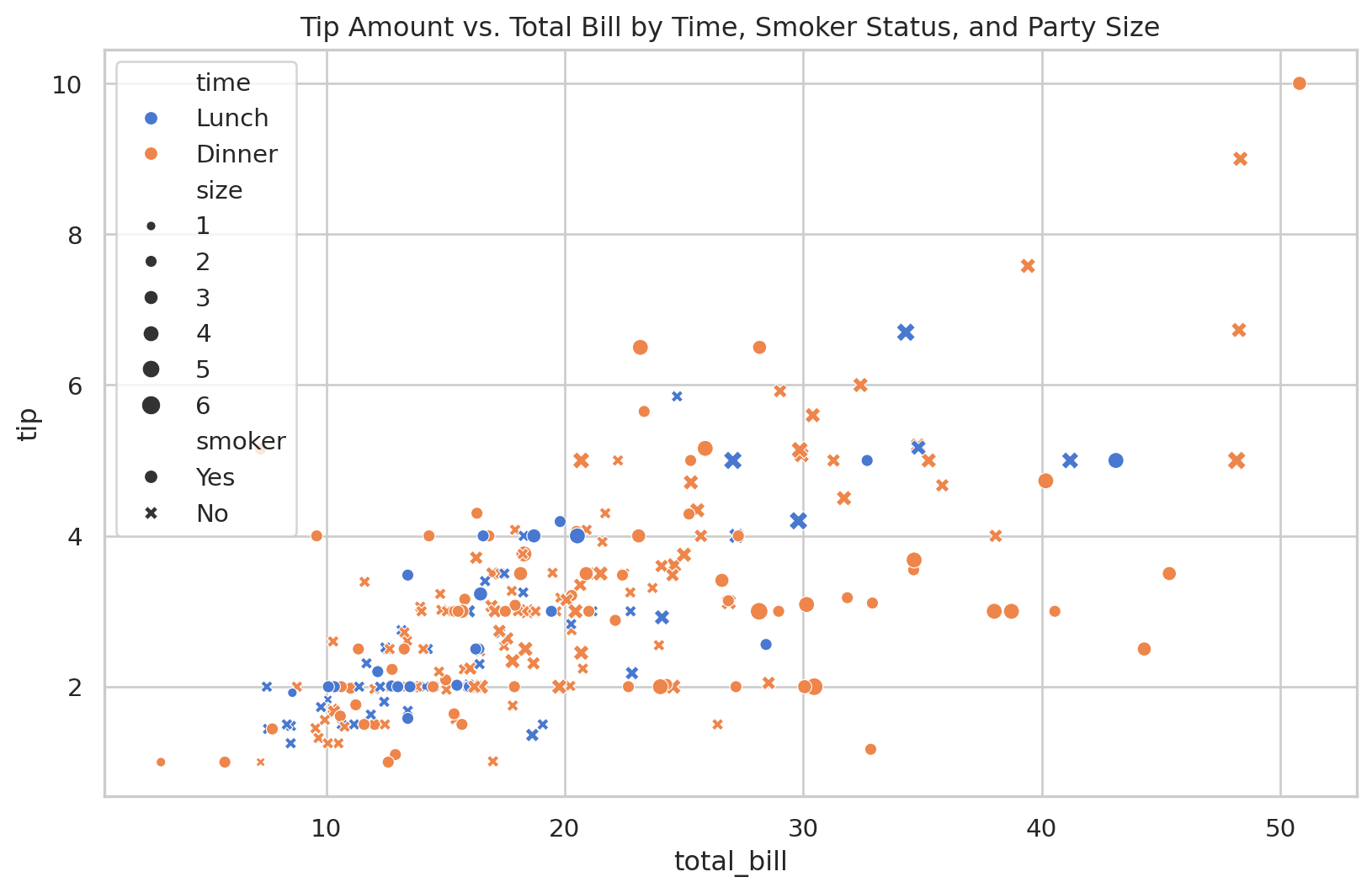
scatterplot 是 Seaborn 的明星函数之一。除了基本的 x-y 关系,它还能通过 hue, style, size 等参数,将多达五个维度的信息压缩到一张二维图表中,极大地提升了信息密度。
import seaborn as snsimport matplotlib.pyplot as plt= sns.load_dataset("tips" )= (10 , 6 ))# hue: 按 'time' (晚餐/午餐) 对点进行着色 # style: 按 'smoker' (是否吸烟) 改变点的形状 # size: 按 'size' (用餐人数) 改变点的大小 = tips, x= "total_bill" , y= "tip" , hue= "time" , style= "smoker" , size= "size" )# 添加一个更具信息量的标题 'Tip Amount vs. Total Bill by Time, Smoker Status, and Party Size' )
2. 分类图 (Categorical Plot) - 小提琴图 (Violin Plot)
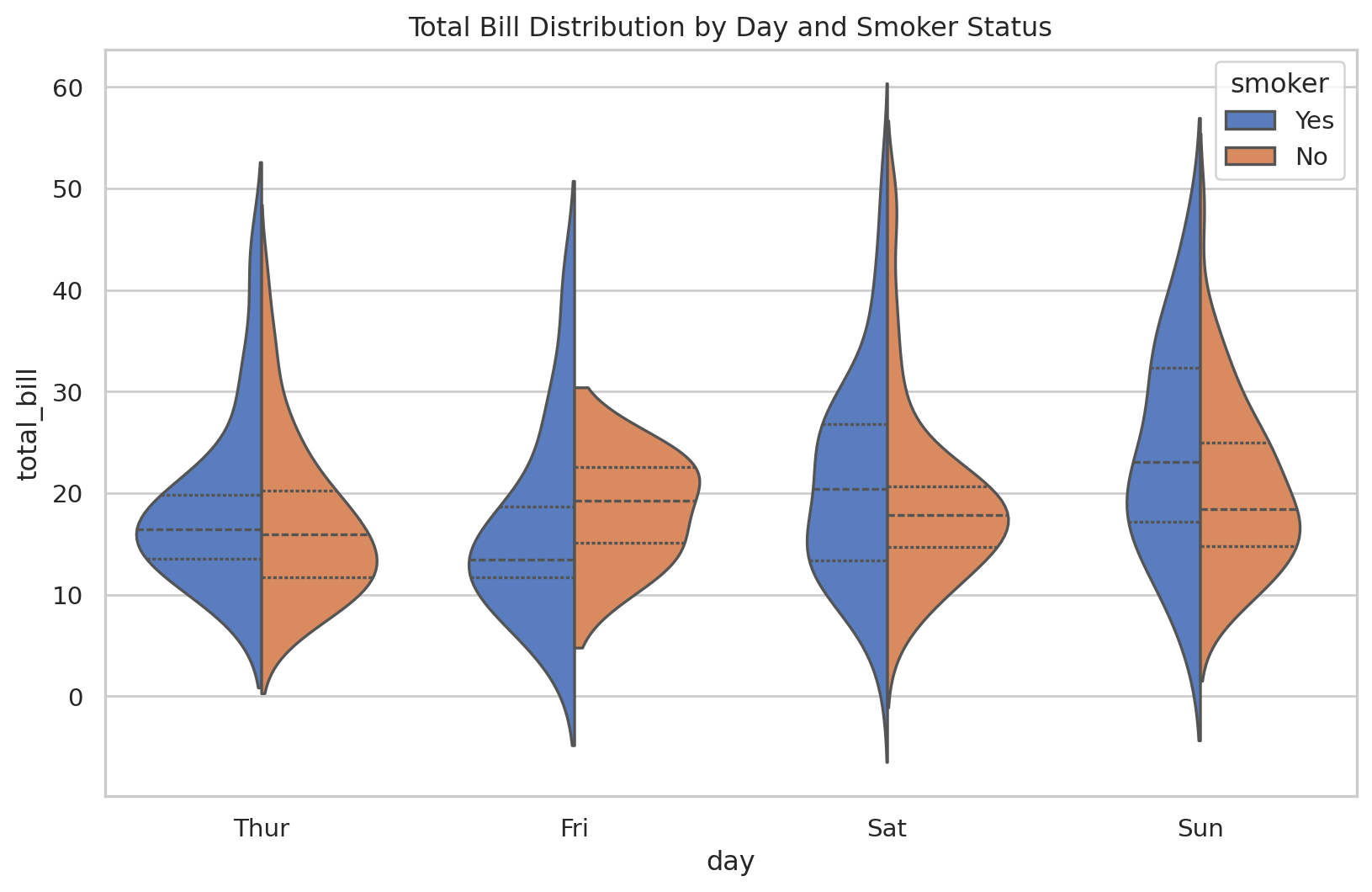
当箱形图(Box Plot)不足以展示数据分布的细节时,小提琴图是绝佳的替代品。它将箱形图与核密度估计(KDE)图相结合,不仅展示了数据的四分位数,还通过外部的形状展示了数据的完整分布密度,尤其适合于比较多组数据的分布形态。
import seaborn as snsimport matplotlib.pyplot as plt= sns.load_dataset("tips" )= (10 , 6 ))# x: 类别轴 (星期几) # y: 数值轴 (账单总额) # hue: 在每个类别内再按 'smoker' 进行二次分类 # split=True: 将 hue 分类的两个小提琴合并到一起,便于比较 = tips, x= "day" , y= "total_bill" , hue= "smoker" , split= True , inner= "quartile" )'Total Bill Distribution by Day and Smoker Status' )
3. 热力图 (Heatmap)
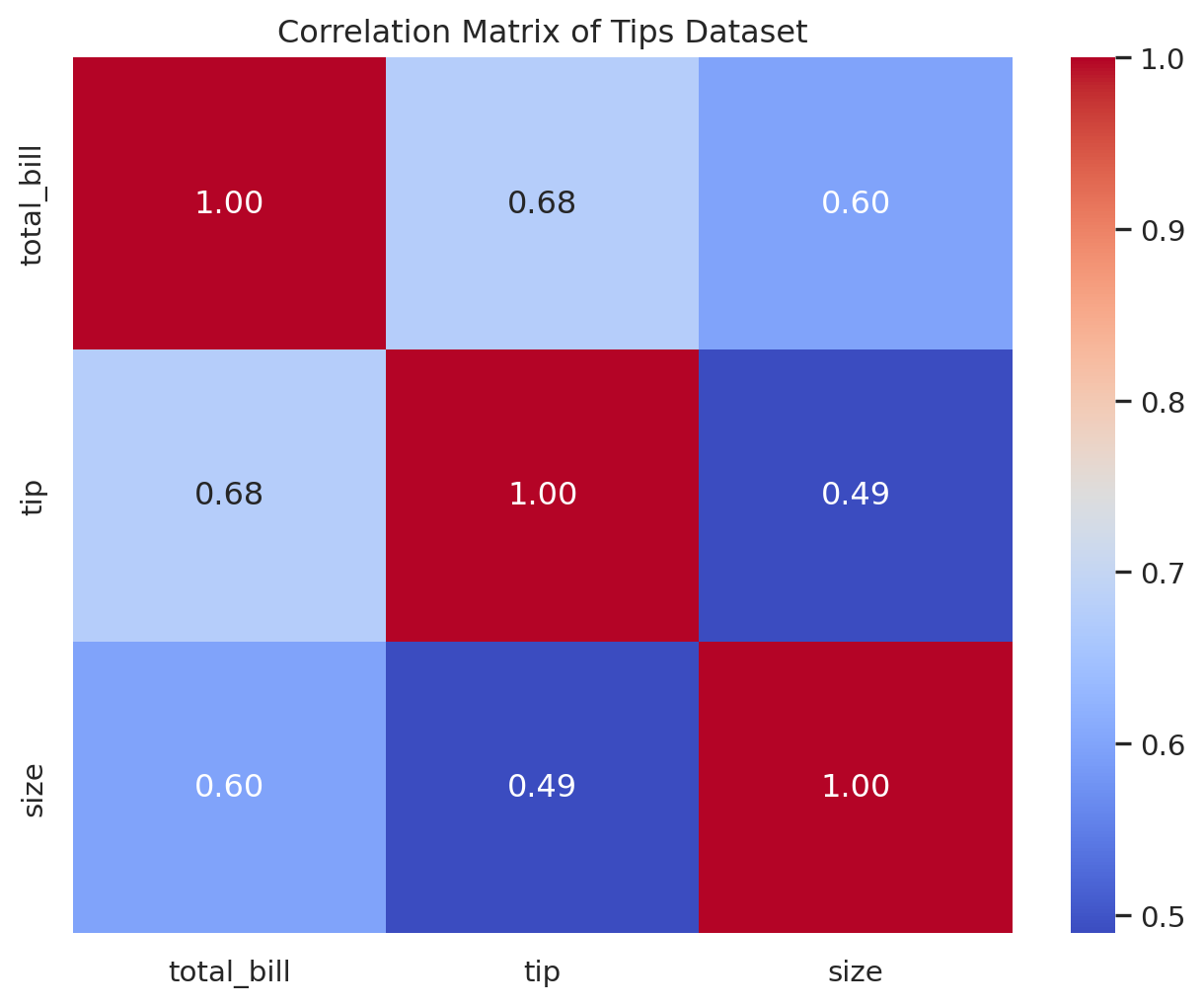
热力图是一种将矩阵数据可视化的强大工具,它通过颜色的深浅来直观地表示数值的大小。它最经典的应用场景是展示变量间的相关性矩阵,让人一眼就能看出哪些变量是强相关的。
import seaborn as snsimport matplotlib.pyplot as pltimport pandas as pdimport numpy as np# 计算 tips 数据集中数值列的相关性矩阵 = tips.select_dtypes(include= np.number)= numeric_cols.corr()= (8 , 6 ))# annot=True: 在每个单元格中显示数值 # fmt=".2f": 数值格式化为两位小数 # cmap='coolwarm': 使用一个冷暖色调的色彩映射,正相关为暖色,负相关为冷色 = True , fmt= ".2f" , cmap= 'coolwarm' )'Correlation Matrix of Tips Dataset' )
4. 配对图 (Pair Plot)
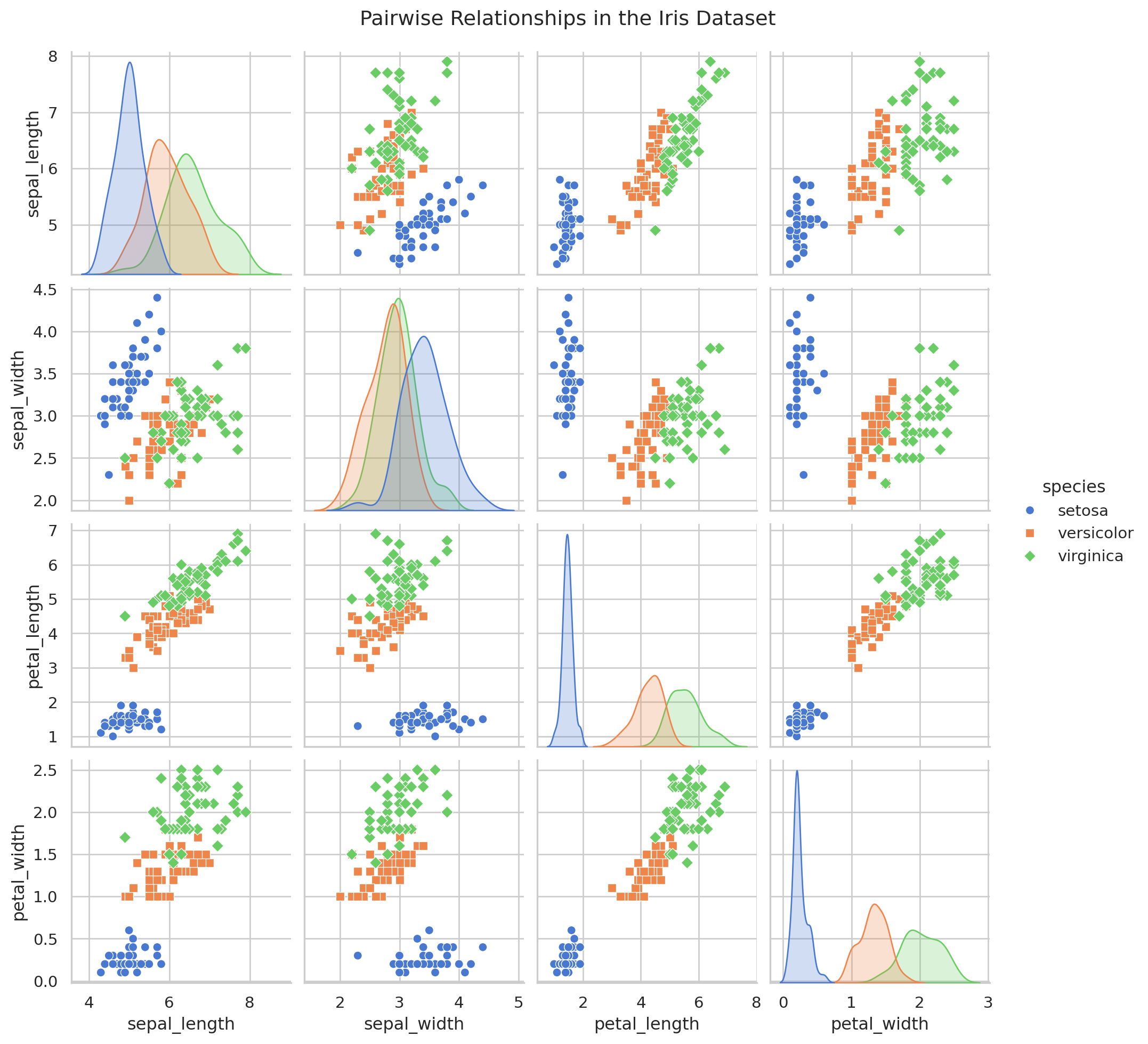
pairplot 是探索性数据分析(EDA)的终极武器。它能快速生成数据集中所有数值变量两两之间的关系图矩阵。在矩阵的对角线上,是每个变量自身的分布直方图或核密度图;在非对角线的位置,是两个变量之间的散点图。这让你能够在一个宏观的视角下审视整个数据集的结构。
import seaborn as snsimport matplotlib.pyplot as plt# 加载著名的鸢尾花数据集 = sns.load_dataset("iris" )# hue="species": 根据花的品种对所有图表进行着色,这使得不同类别间的差异一目了然 # markers: 为不同品种指定不同的标记形状,增强区分度 = "species" , markers= ["o" , "s" , "D" ])'Pairwise Relationships in the Iris Dataset' , y= 1.02 ) # 添加总标题
✨ Plotly:交互式图表的未来
当静态图表无法满足你的探索需求时,Plotly 便登场了。Plotly 是一家科技公司,也是一个强大的 Python 库,其核心目标是创建具有丰富交互能力的、出版物级别的图表。用户可以缩放、平移、选择数据区域,以及通过鼠标悬停查看精确的数值。这极大地增强了数据探索的深度和广度。Plotly Express 作为其高级接口,秉承“用最少的代码做最多的事”的原则,让创建复杂的交互式图表变得前所未有的简单。
创建交互式图表
Plotly 生成的图表本质上是 JSON 数据结构,由 Plotly.js(一个 JavaScript 库)在浏览器中进行渲染。这意味着你可以轻松地将它们嵌入到网页、Jupyter Notebook、或者导出为独立的 HTML 文件。
1. 交互式散点图
这个例子展示了 Plotly Express 如何仅用一行核心代码就创建一个信息丰富的交互式散点图。
import plotly.express as px# Plotly Express 内置了大量方便的数据集,包括著名的 Gapminder 数据 = px.data.gapminder().query("year==2007" )# x, y, color, size, hover_data 等参数都直接对应 DataFrame 的列名 = px.scatter(gapminder,= "gdpPercap" , # x轴:人均GDP = "lifeExp" , # y轴:预期寿命 = "continent" , # 点的颜色:按大洲划分 = 'pop' , # 点的大小:按人口划分 = "country" ,# 鼠标悬停时显示的名称 = True , # x轴使用对数尺度,以便更好地展示GDP差异 = 60 ) # 控制点的最大尺寸 = 'GDP per Capita vs. Life Expectancy (2007)' )
2. 交互式地图(Choropleth Map)
地理空间可视化是 Plotly 的一大亮点。制作等值区域图(Choropleth Map)非常直观,你只需要提供地理位置编码(如国家代码)和对应的数值即可。
import plotly.express as px# 同样使用 Gapminder 数据,但这次是多年的数据 = px.data.gapminder()# animation_frame: 指定按'year'列创建动画帧 # animation_group: 指定'country'作为动画中保持一致的对象 # color_continuous_scale: 指定连续颜色的主题 # projection: 选择地图的投影方式 = px.choropleth(gapminder_all_years,= "iso_alpha" , # 使用 ISO Alpha-3 国家代码进行地理定位 = "lifeExp" , # 区域的颜色深浅由预期寿命决定 = "country" , # 悬停名称 = "year" ,# 创建一个时间滑块动画 = px.colors.sequential.Plasma,= "Global Life Expectancy Over Time" )
3. 3D 散点图
Plotly 让 3D 可视化变得触手可及。你可以通过鼠标拖拽来自由地旋转、缩放和平移 3D 场景,从任何角度观察数据的空间分布。
import plotly.express as px# 加载鸢尾花数据集 = px.data.iris()# 创建一个 3D 散点图,探索三个花瓣/花萼特征之间的关系 = px.scatter_3d(iris,= 'sepal_length' ,= 'sepal_width' ,= 'petal_width' ,= 'species' ,= 'species' , # 为不同种类使用不同形状的标记 = "3D View of Iris Dataset Features" )= dict (l= 0 , r= 0 , b= 0 , t= 40 )) # 调整边距以更好地展示
🤔 如何选择合适的工具?
面对如此多的选择,关键在于理解你的核心需求。下面是一个更详细的决策指南:
Matplotlib 极致控制力 :可定制图表的每一个细节。稳定、成熟,是学术出版的首选。1. 需要精确布局和标注的学术论文 图表。<br>2. 创建全新的、非标准的图表类型。<br>3. 作为其他库(如 Seaborn)的底层进行微调。
1. 快速制作交互式图表。<br>2. 简单的探索性数据分析(代码相对繁琐)。
Seaborn 统计之美 :API 简洁优雅,专为统计分析设计。与 Pandas 结合极佳,默认样式美观。1. 探索性数据分析 (EDA) ,快速洞察数据分布和关系。<br>2. 展示变量间的统计相关性(如相关性热图、回归图)。
1. 高度定制化的非统计类图表。<br>2. 构建复杂的交互式仪表盘。
Plotly 现代交互 :图表美观、交互体验流畅。支持 3D、动画和地理图,易于分享 (HTML)。1. 商业智能 (BI) 报告 和在线演示。<br>2. 创建需要用户交互探索的 Web 图表。<br>3. 制作引人注目的动画和 3D 可视化。
1. 对性能要求极高的超大规模数据集实时渲染。<br>2. 简单的静态图表(可能有些大材小用)。
Bokeh 应用构建 :专为 Web 设计,可构建复杂的数据应用 。支持流数据,交互逻辑强大。1. 构建复杂的仪表盘 ,包含图表联动、下拉菜单、滑块等控件。<br>2. 需要实时更新数据的流数据监控 应用。
1. 静态图表的制作(不如 Matplotlib/Seaborn 直接)。<br>2. 对非 Web 输出(如 PDF, PNG)有高质量要求时。
经验法则 :
日常探索与分析 :你的起点应该是 Seaborn 。它能用最少的代码满足你 80% 的统计绘图需求。当需要交互时,无缝切换到 Plotly Express 。发表论文或书籍 :使用 Seaborn 或 Plotly 进行初步绘图,然后用 Matplotlib 对字体、分辨率、布局等细节进行最后的精修,以满足出版要求。构建交互式 Web 应用 :如果你的目标是一个独立的、可交互的网页或仪表盘,Plotly 和 Bokeh 是你的不二之选。Plotly 在单图表的华丽度和易用性上略有优势,而 Bokeh 在构建多组件联动的复杂应用时提供了更强的灵活性。